
{kind=link}
เมื่อ AI โมเดลขนาดใหญ่ กลายเป็น Open Source นักพัฒนาทั่วโลกสามารถต่อยอด การนำโมเดลขนาดใหญ่ มาเป็นการพัฒนา AI ทำงานที่หลากหลาย อยู่ในคอมพิวเตอร์ ที่ประกอบขึ้นมาเพียงพอที่จะให้ AI ทำงานได้อย่างรวดเร็ว เป็นสิ่งที่ไม่ได้ซับซ้อนและเข้าถึงยาก
ความแตกต่างทางเทคนิค: LLMs vs. Transformer vs. Foundation Model
เวลามีการพูดคุยเรื่อง Generative AI ผมและทีมงาน เราจะหลุดการพูดถึง LLMs (Large Language Model) บ่อยครั้ง และในการพูดคุยในการพัฒนา AI เราก็จะพูดอีกหลายคำเช่น GPT GPT (Generative Pre-trained Transformer) T คือ Transformer และการพัฒนา Foundation Model ซึ่งทั้งหมดล้วนแตกต่างกัน แต่มีความใกล้กันในแง่การถึงพูดถึง ในมุมพื้นฐานหรือ Business เราคงไม่กังวลมากนักสำหรับคำจำกัดความ แต่สำหรับในการพัฒนาเราต้องเข้าใจความแตกต่าง เพื่อทำเจาะจงความสำคัญ และความเข้มข้นของการพัฒนา AI Solutions และการนำไปใช้ในการสร้างโจทย์งาน AI ซักงานหนึ่งในระดับลึก ซึ่งจะขอพูด Transformer
Transformer
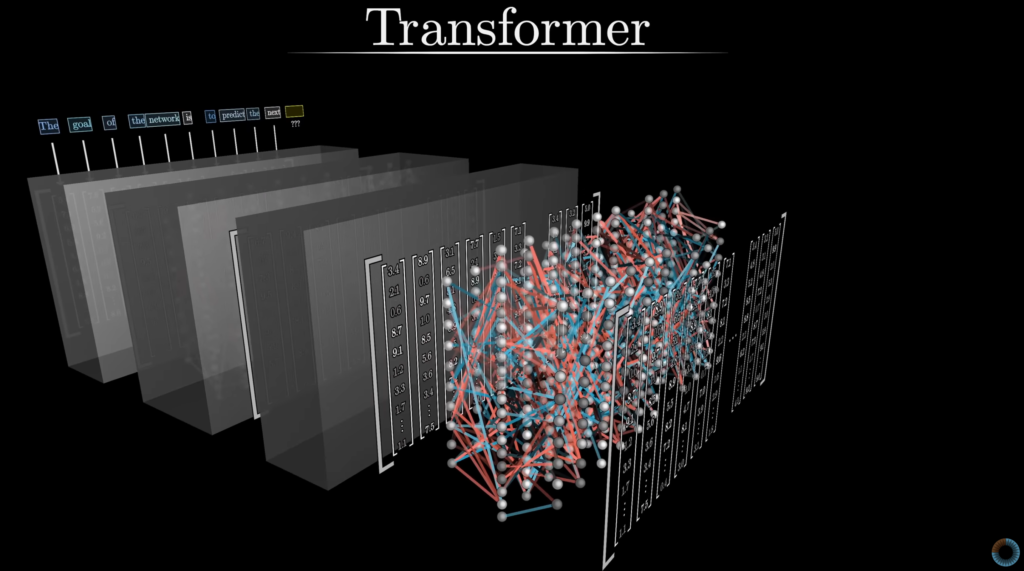
- สถาปัตยกรรม Transformer เป็นนวัตกรรมที่เกิดขึ้นในปี 2017 โดยทีมวิจัยของ Google (ในงาน “Attention Is All You Need”) ซึ่งเปลี่ยนแปลงวิธีการประมวลผลข้อมูลภาษาและลำดับข้อมูลไปอย่างสิ้นเชิง
- สถาปัตยกรรมพื้นฐาน: Transformer เป็นโครงสร้างของนิวรัลเน็ตเวิร์ก หรือ Deep Learning ที่ใช้กลไก self-attention ซึ่งช่วยให้โมเดล “ดู” คำทั้งหมดในประโยคพร้อมกันและตัดสินความสำคัญของแต่ละคำได้ มีสถาปัตยกรรมพื้นฐาน: Transformer เป็นโครงสร้างของนิวรัลเน็ตเวิร์กที่ใช้กลไก self-attention ซึ่งช่วยให้โมเดล “ดู” คำทั้งหมดในประโยคพร้อมกันและตัดสินความสำคัญของแต่ละคำได้
- พื้นฐานของ LLMs: LLMs ส่วนใหญ่ถูกสร้างขึ้นบนโครงสร้าง Transformer แต่ Transformer เองเป็นเพียงสถาปัตยกรรมพื้นฐานที่สามารถประยุกต์ใช้กับงานอื่น ๆ ได้ด้วย
แนวคิดหลักของ Transformer ที่มาต่อยอดให้ LLMs เข้าใจภาษาธรรมชาติ
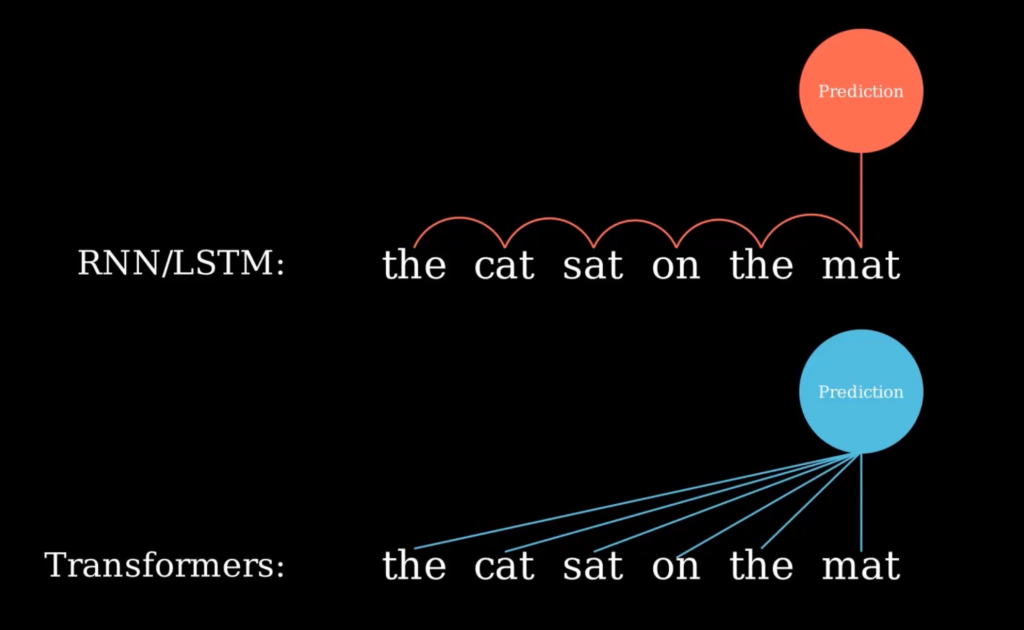
- Self-Attention Mechanism:
Transformer ใช้กลไก self-attention เพื่อประเมินความสัมพันธ์ระหว่างคำในประโยคทั้งหมดในครั้งเดียว โดยไม่ต้องประมวลผลแบบลำดับ (sequential processing) เหมือนกับ RNN ซึ่งช่วยให้สามารถประมวลผลคำหลายๆ คำพร้อมกัน (parallel processing) จึงช่วยลดเวลาในการฝึกอบรมและเพิ่มประสิทธิภาพในการประมวลผลข้อมูลที่ยาวและซับซ้อนได้ - Encoder-Decoder Architecture:
โครงสร้างพื้นฐานของ Transformer แบ่งออกเป็น 2 ส่วนหลักคือ- Encoder: รับข้อมูลเข้า (เช่น ประโยคภาษาอังกฤษ) แล้วแปลงเป็นตัวแทน (representation) ที่สรุปความหมายของแต่ละคำในบริบท
- Decoder: รับข้อมูลจาก Encoder และข้อมูลที่สร้างขึ้นก่อนหน้านี้ (ในรูปแบบ autoregressive) เพื่อสร้างคำหรือประโยคในภาษาที่ต้องการ (เช่น ภาษาฝรั่งเศส) โดย decoder จะใช้กลไก self-attention แบบที่มีการจำกัด (causal masking) เพื่อให้คำที่กำลังสร้างไม่สามารถเข้าถึงข้อมูลในอนาคตได้
ตัวอย่างการทำงาน ลองนึกถึงการแปลประโยค “I like this course” เป็นภาษาฝรั่งเศส
- Self-Attention: โมเดลจะประเมินความสัมพันธ์ระหว่าง “I” กับ “like” รวมทั้ง “this” กับ “course” เพื่อให้แน่ใจว่าการแปลคำว่า “like” นั้นถูกต้องตามบริบท และการแปลคำว่า “this” ต้องพิจารณาจากคำว่า “course” ที่เป็นคำนามและอาจมีการผันตามเพศ
- Encoder และ Decoder: Encoder จะแปลงประโยคภาษาอังกฤษให้เป็นตัวแทนที่เข้าใจบริบททั้งหมด แล้ว Decoder จะสร้างคำในภาษาฝรั่งเศสทีละคำ โดยใช้ข้อมูลจาก Encoder เป็นตัวช่วยในการตัดสินใจเลือกคำที่เหมาะสม
Transformer ไม่เพียงแต่ช่วยเพิ่มประสิทธิภาพในงานแปลภาษาเท่านั้น แต่ยังเป็นรากฐานที่ทำให้เกิดโมเดลภาษาและโมเดลหลากหลายสาขาที่มีขนาดใหญ่ขึ้น (Large Language Models) ที่เราเห็นในปัจจุบัน อีกทั้งยังนำไปสู่การพัฒนาในด้าน computer vision, speech recognition และงานด้านอื่นๆ ที่ต้องประมวลผลข้อมูลในลักษณะลำดับ
การคิดค้น Transformer โดย Google ถือเป็นการปฏิวัติวงการ AI เพราะมันเปลี่ยนวิธีการเข้าใจและประมวลผลข้อมูลภาษาธรรมชาติอย่างสิ้นเชิง ด้วยการใช้ self-attention และการประมวลผลแบบขนาน ทำให้โมเดลสามารถฝึกและนำไปใช้ในงานจริงได้อย่างรวดเร็วและมีประสิทธิภาพสูง ผมอธิบายส่วนนี้ยาวหน่อยเพราะเป็นพื้นฐานสำคัญ
LLMs
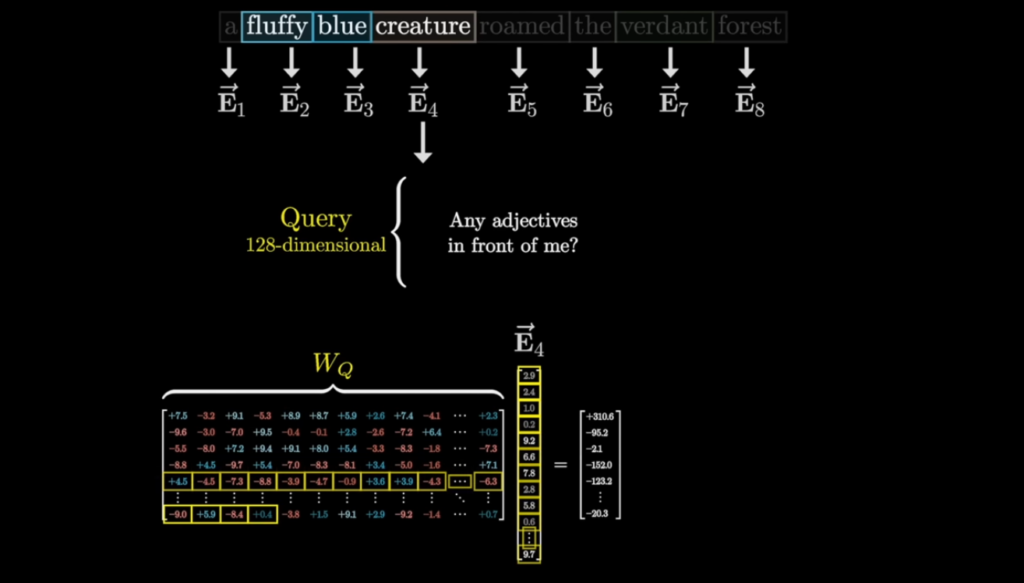
Transformer ป็นรากฐานที่ทำให้เกิดโมเดลภาษาและโมเดลหลากหลายสาขาที่มีขนาดใหญ่ขึ้น (Large Language Models) จนกลายเป็นส่วนสำคัญของ Generative AI ที่ใช้งานกันทั่วโลก เขียนเรียงความ, ตอบคำถามต่าง ๆ
LLMs ต่อยอดจากสถาปัตยกรรม Transformer โดยขยายขนาดโมเดลและปริมาณข้อมูลที่ใช้ฝึกให้ใหญ่ขึ้นมาก LLMs ใช้ self-attention และ deep learning เพื่อเข้าใจและสร้างข้อความในภาษามนุษย์อย่างเป็นธรรมชาติ โมเดลเหล่านี้ถูกฝึกด้วยข้อมูลจากหลากหลายแหล่ง เช่น หนังสือ บทความ และเว็บไซต์ เพื่อให้เข้าใจความหมายและบริบทของคำในระดับลึก ตัวอย่างที่โดดเด่นคือ GPT-4, PaLM, LLaMA ที่สามารถสนทนา สรุปความ และเขียนโค้ดได้ LLMs ยังสามารถเรียนรู้แบบ zero-shot หรือ few-shot learning เพื่อทำงานที่ไม่เคยเจอมาก่อนได้อย่างมีประสิทธิภาพ
ในอนาคต LLMs อาจกลายเป็นพื้นฐานของ AGI (Artificial General Intelligence) ที่สามารถเรียนรู้และปรับตัวได้เหมือนมนุษย์ โดยสรุป เราต่อยอด จน LLM มีขนาดที่ใหญ่ถูกฝึกด้วยข้อมูลจากหลากหลายแหล่ง และซับซ้อนมากขึ้น ลงรายละเอียดส่วนนี้ให้มากขึ้นด้านล่างนี

- ขนาดและความซับซ้อน: LLMs จะมีขนาดใหญ่และความซับซ้อนที่สูงมาก ซึ่งมักถูกอ้างด้วยขนาดของจำนวนพารามิเตอร์ (เช่น GPT-3 มี 175 พันล้านพารามิเตอร์) ทำให้สามารถเก็บข้อมูลและความรู้ที่หลากหลายจากการฝึกด้วยข้อมูลจำนวนมาก เน้นการประมวลผลภาษา: ถูกออกแบบมาเพื่อเข้าใจและสร้างข้อความในภาษามนุษย์ เช่น การแปลภาษา, การตอบคำถาม, การสรุปบทความ และการสร้างเนื้อหาใหม่ การเข้าใจภาษาธรรมชาตินี้เอง ปลดล๊อคการสั่งงาน คอมพิวเตอร์ ด้วยภาษาที่ไม่ใช่โปรแกรมเมอร์ทำให้การใช้งาน เกิดขึ้นได้กับทุกคน
- ยกตัวอย่าง LLM ที่ชัดเจนเช่น Google Gemini หรือ ChatGPT: ที่เปรียบเสมือน “ห้องสมุดอัจฉริยะ” ที่มีหนังสือหลายล้านเล่ม ซึ่งสามารถให้คำตอบหรือสร้างบทสนทนาในภาษาที่เป็นธรรมชาติได้ ซึ่งโมเดล LLM ก็จะถูกสร้างให้ตอบคำถาม ทำงานได้หลากหลาย อย่าง GPT-4: เป็นโมเดลที่มีความสามารถในการเขียนเรียงความ, ตอบคำถามเฉพาะด้าน, หรือแม้กระทั่งสร้างโค้ดโปรแกรม
Foundation Models โมเดลพื้นฐาน
LLMs (Large Language Models) เป็นผลลัพธ์จากการต่อยอดสถาปัตยกรรม Transformer ซึ่งใช้ Self-Attention ในการจับความสัมพันธ์ระหว่างคำทั้งหมดในประโยคพร้อมกัน โดย LLMs อย่าง GPT-3 หรือ PaLM หรือโมเดล GPT ใหม่ ๆ ก็มักมีจำนวนพารามิเตอร์สูงมาก ทำให้สามารถเรียนรู้โครงสร้างภาษาได้ลึกซึ้งและครอบคลุม อย่างไรก็ตาม จุดเริ่มต้นยังคงมาจาก Transformer ที่เป็นเหมือน “เครื่องยนต์” พื้นฐาน ใช้กลไก attention เพื่อเข้าใจและประมวลผลข้อมูลอย่างมีประสิทธิภาพ
ในอีกมุมหนึ่ง Foundation Model เป็นแนวคิดที่กว้างขึ้น โดยโมเดลเหล่านี้ถูกฝึกด้วยข้อมูลหลากหลายประเภทในปริมาณมหาศาล เพื่อให้มี “ความเข้าใจพื้นฐาน” (general understanding) ซึ่งสามารถนำไปปรับใช้กับงานเฉพาะด้านได้อย่างง่ายดาย ตัวอย่างเช่น BERT, GPT หรือ CLIP ล้วนเป็น Foundation Models เพราะได้รับการฝึกในระดับเบื้องต้นบนชุดข้อมูลขนาดใหญ่ จนกระทั่งพร้อมนำไปปรับแต่ง (fine-tune) เพิ่มเติมตามความต้องการ เช่น การวิเคราะห์ข้อความ หรือการสร้างภาพ
ตัวอย่างเช่น CLIP ถูกฝึกด้วยภาพและข้อความจำนวนมาก จึงเข้าใจความสัมพันธ์ระหว่างรูปภาพกับคำอธิบาย ทำให้สามารถนำไปปรับใช้ในงานค้นหาภาพหรือวิเคราะห์เนื้อหาได้ ขณะที่ LLM อย่าง GPT-3 เน้นการสร้างประโยคและโต้ตอบเชิงภาษา โดยอาศัยพารามิเตอร์จำนวนมาก สะท้อนความรู้เชิงสถิติของภาษา ซึ่งเห็นได้จากความสามารถในการตอบคำถามหรือแต่งข้อความซับซ้อน
Transformer เป็นองค์ประกอบสำคัญ เพราะเปิดโอกาสให้โมเดลประมวลผลคำพร้อมกัน ทำให้การฝึกและอนุมานเร็วขึ้น และจัดการบริบทได้ยาว Foundation Model อาจรองรับข้อมูลได้หลายรูปแบบ เช่น ภาพ ข้อความ หรือเสียง เพื่อใช้งานหลากหลาย ในขณะที่ LLMs มุ่งเน้นด้านภาษาขนาดใหญ่ ส่วน Transformer เป็นสถาปัตยกรรมเบื้องหลังที่เสริมประสิทธิภาพ สรุปแล้ว LLMs เน้นประมวลผลภาษาด้วยโมเดลยักษ์ Transformer คือโครงสร้าง และ Foundation Model คือแนวคิดโมเดลพื้นฐานที่ปรับใช้ได้หลายด้าน
- โดยสรุป โมเดลพื้นฐาน: เป็นแนวคิดที่กว้างขึ้น ซึ่งรวมถึงโมเดลที่ถูกฝึกมาในระดับเบื้องต้นบนข้อมูลที่หลากหลายและสามารถปรับใช้ในงานเฉพาะด้านได้
- ความยืดหยุ่น: นอกจากการประมวลผลภาษาแล้ว Foundation Models ยังครอบคลุมงานที่เกี่ยวกับข้อมูลภาพ เสียง และข้อมูลชนิดอื่น ๆ ทำให้มีความยืดหยุ่นและครอบคลุมมากขึ้น
Multi-Modal ต่างกันกับ Foundation Model
ส่วนในระยะหลังเราจะได้ยินคำว่า Multi-Modal ต่างกันกับ Foundation Model มั้ย
Multi-modal หมายถึงโมเดลที่สามารถรับและประมวลผลข้อมูลจากหลายช่องทาง (modalities) เช่น ข้อความ รูปภาพ เสียง หรือแม้กระทั่งวิดีโอ ในขณะที่ Foundation Model คือแนวคิดของโมเดลที่ถูกฝึกด้วยชุดข้อมูลมหาศาลในระดับเบื้องต้น (pre-training) เพื่อสร้าง “ฐานความรู้” ที่ครอบคลุมและสามารถนำไปปรับใช้ในงานเฉพาะทาง (fine-tuning) ได้
โดยทั่วไป Foundation Models ถูกออกแบบให้เป็นโมเดลพื้นฐานที่สามารถต่อยอดไปใช้งานหลากหลายด้าน เช่น การแปลภาษา การสรุปข้อความ หรือแม้กระทั่งการทำงานในด้านภาพและเสียง ซึ่งโมเดลเหล่านี้บางส่วนก็เป็น multi-modal ด้วย เช่น CLIP, DALL-E ที่ได้รับการฝึกด้วยข้อมูลทั้งจากข้อความและภาพ ทำให้สามารถเข้าใจความสัมพันธ์ระหว่างภาพกับคำอธิบายได้
อย่างไรก็ตาม ไม่ใช่ทุก Foundation Model จะเป็น multi-modal บางโมเดลอาจถูกออกแบบให้รองรับเพียงหนึ่งประเภทของข้อมูล (เช่น GPT-3 ที่เน้นการประมวลผลภาษา) ในขณะที่ multi-modal model จะเน้นการรวมหลายช่องทางข้อมูลเข้าด้วยกัน ซึ่งช่วยให้ระบบมีความยืดหยุ่นและสามารถใช้งานได้ในหลายบริบท
สรุปแล้ว Multi-modal คือคุณสมบัติของโมเดลที่รองรับข้อมูลหลายประเภท ส่วน Foundation Model คือแนวทางการฝึกโมเดลที่ให้ฐานความรู้กว้าง ซึ่งอาจรวมถึงโมเดลที่เป็น multi-modal หรือ uni-modal ขึ้นอยู่กับการออกแบบและชุดข้อมูลที่ใช้ฝึกอบรม
บทสรุปและอนาคตของการพัฒนา AI ด้วย Open-Source LLMs
จากที่ได้อธิบายความแตกต่างระหว่าง Transformer, LLMs, และ Foundation Models ไปแล้ว เราเห็นได้ชัดว่าการเปิดให้เข้าถึงโมเดลขนาดใหญ่แบบ Open Source นั้นเป็นก้าวสำคัญที่ช่วยเร่งการพัฒนา AI อย่างก้าวกระโดด นักพัฒนาสามารถนำ LLMs ที่เป็น Foundation Models ซึ่งมีรากฐานมาจากสถาปัตยกรรม Transformer ที่ทรงประสิทธิภาพ มาต่อยอดและปรับแต่งให้เหมาะสมกับงานเฉพาะด้านได้อย่างรวดเร็ว ไม่ว่าจะเป็นงานประมวลผลภาษาธรรมชาติ การวิเคราะห์ภาพ หรือการประมวลผลข้อมูลแบบ Multi-modal ความยืดหยุ่นและความสามารถในการปรับแต่งนี้เองที่ทำให้ AI กลายเป็นเครื่องมือที่ทรงพลังและเข้าถึงได้ง่ายขึ้น
ความสามารถในการประมวลผลแบบขนานของ Transformer ซึ่งเป็นหัวใจสำคัญของ LLMs ทำให้การฝึกอบรมโมเดลและการอนุมานรวดเร็วขึ้น และด้วยการเปิด source code จึงลดอุปสรรคด้านเทคโนโลยีและต้นทุน ส่งผลให้บุคคลและองค์กรต่างๆ สามารถเข้าถึงและใช้ประโยชน์จากเทคโนโลยี AI ได้มากขึ้น การพัฒนาแบบ Open Source ยังส่งเสริมให้เกิดความร่วมมือและการแบ่งปันความรู้ในวงกว้าง นำไปสู่การพัฒนา AI ที่มีความก้าวหน้าและเป็นประโยชน์ต่อสังคมมากยิ่งขึ้น
ในอนาคต เราอาจเห็นการพัฒนา LLMs ที่มีความสามารถและความเชี่ยวชาญเฉพาะด้านเพิ่มขึ้น โดยอาศัยการปรับแต่งโมเดลพื้นฐาน รวมถึงการผสานความสามารถแบบ Multi-modal เพื่อสร้าง AI ที่สามารถทำงานได้หลากหลายและตอบโจทย์ความต้องการที่ซับซ้อนของมนุษย์ได้อย่างมีประสิทธิภาพ การเข้าถึง Open Source LLMs จึงเป็นกุญแจสำคัญที่ช่วยปลดล็อกศักยภาพของ AI และนำไปสู่การสร้างนวัตกรรมใหม่ๆ ในหลากหลายสาขาอาชีพและอุตสาหกรรม การเรียนรู้และทำความเข้าใจถึงพื้นฐานอย่าง Transformer, LLMs, และ Foundation Models จึงเป็นสิ่งจำเป็นอย่างยิ่งสำหรับนักพัฒนา AI ในยุคปัจจุบันและอนาคตอันใกล้
อย่างไรก็ตาม การนำ LLMs มาใช้งานจริงอย่างมีประสิทธิภาพนั้นต้องการมากกว่าแค่ความเข้าใจในพื้นฐานทางทฤษฎี การออกแบบระบบ AI ที่แข็งแกร่ง มีประสิทธิภาพ และสามารถปรับขนาดได้ นั้นจำเป็นต้องอาศัยความรู้และทักษะด้าน AI Engineering ซึ่งเป็นศาสตร์ที่บูรณาการความรู้ด้านต่างๆ ตั้งแต่การเลือกโมเดล การฝึกอบรม การปรับแต่ง การใช้งาน และการบริหารจัดการ เพื่อให้ได้ระบบ AI ที่สามารถทำงานได้จริง และตอบโจทย์ความต้องการทางธุรกิจ ในบทความต่อไป เราจะเจาะลึกไปยังโลกของ AI Engineering เพื่อให้ผู้อ่านมีความเข้าใจที่ลึกซึ้งยิ่งขึ้น ติดตามบทความต่อไปได้เลยครับ!