

ระหว่างแปลหนังสือ และต้องทำความเข้าใจอย่างมากเรื่อง ทฤษฏี ความกดดันคือ ต้องเล่าเรื่องให้เข้าใจง่าย ไม่งั้นผู้อ่านก็คงงง ถ้าผมคนแปลเองก็ยังไม่เคลีย จะแปลแบบไม่เคลียก็ทำได้ แต่เราก็ไม่ควรทำ (บางเรื่องลึกมากอย่างการแพทย์ ขีววิทยา หรือฟิสิกส์ เสมือนต้องกลับไปนั่งเรียนเอกวิชานั้นเลยทีเดียว โชคดีมี AI ช่วยทำให้ทำความเข้าใจเรื่องนั้น ๆ ได้เร็วขึ้นมาก)
มาตรฐานการวัด AI
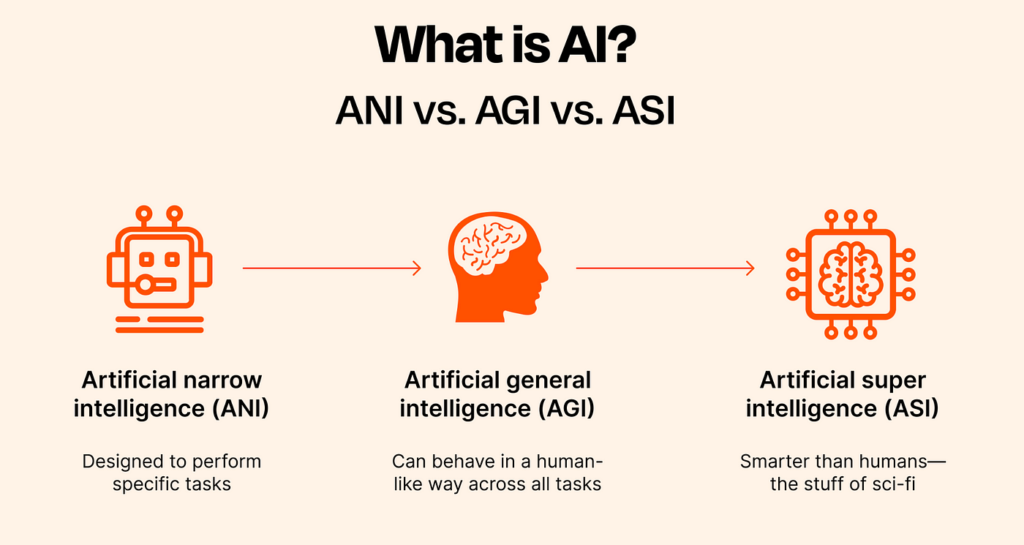
เราพูดเรื่อง “Artificial General Intelligence (AGI)” กันเยอะ เป้าหมายของการพัฒนา AI ในตอนนี้มุ่งไปที่การเป็น AGI ปัญญาประดิษฐ์ทั่วไป (Artificial General Intelligence – AGI) หมายถึงระบบปัญญาประดิษฐ์ที่มีความสามารถในการทำงานทางปัญญาได้หลากหลายเทียบเท่าหรือเหนือกว่ามนุษย์ ซึ่งแตกต่างจากปัญญาประดิษฐ์เฉพาะทาง (Artificial Narrow Intelligence – ANI) ที่ถูกออกแบบมาเพื่อทำงานเฉพาะด้านเท่านั้น นิยามของ AGI1
ความฉลาดของ โมเดล LLM(Large Language Model) เป็นส่วนสำคัญที่ทำให้เราคุยกับ AI ได้ เราก็มี การใช้ชุดข้อมูลทดสอบหลายวิธี และ Benchmark มาตรฐานก็มีหลากหลาย ไม่ว่าจะการประเมินด้วยผู้เชี่ยวชาญ ว่าสามารถประมวลผลได้ใกล้เคียงกับมนุษย์หรือไม่ มาตรฐาน GLUE2 วัดความสามารถในการเข้าใจภาษา SuperGLUE3 ไว้วัดความสามารถทางภาษาที่มีความซับซ้อนมากขึ้น หรือ SQuAD4 การวัดการตอบคำถาม
ส่วนสำคัญของ AI ที่ปฏิวัติโลกคือ การเข้าใจภาษาธรรมชาติ เป็นพื้นฐานของ AGI แล้วอะไรจะมาวัด AGI ล่ะว่าถึงจุดที่เรานิยามความสามารถของ ปัญญาประดิษฐ์ทั่วไป รึยัง ไอที่บอกว่า ระบบปัญญาประดิษฐ์ที่มีความสามารถในการทำงานทางปัญญาได้หลากหลายเทียบเท่าหรือเหนือกว่ามนุษย์ เทียบเท่าแค่ไหนกัน มีมาตรฐานอะไรวัด
{kind=link}
แน่นอนว่าคำตอบอยู่ในหัวข้อบทความแล้ว 😃 Turing Test
ทำความรู้จัก Turing Test
ผมจะพูดว่า Turing Test เป็นคำตอบในการวัด AGI ก็ไม่ถูกต้องนัก เพราะ AGI ในทุกวันนี้ เป็นแนวคิดที่ค่อนข้างกว้าง และยังอยู่ในระดับทฤษฏี ปกติแล้วการจะประเมินความสามารถ หลากหลายและเทียบเท่ามนุษย์นั้น ก็ต้องนั่งนิยามกันอีกเช่นกัน เพราะว่าพื้นฐานของมนุษย์ที่ชาญฉลาด สามารถแก้ไขปัญหาที่มีความซับซ้อนสูงได้ รวมไปถึงการเรียนรู้สถานการณ์ใหม่ ๆ และการปรับตัวให้เข้ากับสภาพแวดล้อมต่าง ๆ
แต่ในหนังสือ หรือผู้เชี่ยวชาญหลายคน ก็ยกให้การวัดความเก่งของ AI ก็เอาแนวคิดของบิดาผู้คิดค้น คอมพิวเตอร์มาใช้ แล้วขยายความต่อ

แอลัน แมธิสัน ทัวริง (Alan Mathison Turing) หรือ สั้นๆ Alan Turing (1912–1954) นักคณิตศาสตร์ นักตรรกศาสตร์ นักรหัสวิทยา และนักวิทยาศาสตร์คอมพิวเตอร์ที่มีบทบาทสำคัญในการวางรากฐานของวิทยาการคอมพิวเตอร์สมัยใหม่ การออกแบบ ออกแบบเครื่องคำนวณอัตโนมัติ (Automatic Computing Engine) ซึ่งเป็นหนึ่งในดีไซน์แรก ๆ ของคอมพิวเตอร์ที่สามารถเก็บโปรแกรมได้
ในฐานะบิดาแห่งวิทยาการคอมพิวเตอร์และปัญญาประดิษฐ์ แนวคิดของเขาจึงสำคัญ
การทดสอบทัวริง (Turing Test) เป็นวิธีการที่เสนอโดยแอลัน ทัวริงในปี พ.ศ. 2493 (ค.ศ. 1950) เพื่อประเมินความสามารถของเครื่องจักรในการแสดงพฤติกรรมที่ชาญฉลาดเทียบเท่าหรือไม่สามารถแยกแยะได้จากพฤติกรรมของมนุษย์
ในการทดสอบนี้ ผู้ประเมินที่เป็นมนุษย์จะสื่อสารกับเครื่องจักรและมนุษย์อีกคนหนึ่งผ่านการสนทนาทางข้อความ หากผู้ประเมินไม่สามารถระบุได้อย่างน่าเชื่อถือว่าใครคือเครื่องจักร แสดงว่าเครื่องจักรนั้นผ่านการทดสอบทัวริง ซึ่งบ่งชี้ว่าเครื่องจักรมีความฉลาดคล้ายมนุษย์ เป็นขั้น AGI ที่คาดหวัง
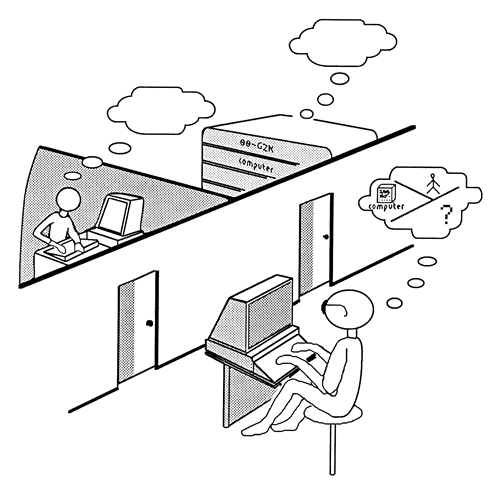

1. สามห้อง ประกอบด้วยบุคคลหนึ่งคน (human), คอมพิวเตอร์ (machine หรือ AI system) และผู้สอบสวน (interrogator)
2. ผู้สอบสวนจะสื่อสารกับทั้งมนุษย์และเครื่องจักรผ่านเครื่องพิมพ์ข้อความ (teleprinter) โดยไม่มีการเห็นหน้าหรือได้ยินเสียงของทั้งสองฝ่าย
3. ผู้สอบสวนมีหน้าที่พยายามระบุว่าใครคือมนุษย์และใครคือเครื่องจักร
4. เครื่องจักรจะพยายามหลอกล่อให้ผู้สอบสวนเชื่อว่ามันคือมนุษย์
5. หากผู้สอบสวนไม่สามารถแยกแยะได้อย่างแน่ชัดว่าใครคือเครื่องจักร แสดงว่าเครื่องจักรได้ผ่านการทดสอบนี้ ซึ่งบ่งชี้ว่ามันมีความสามารถในการแสดงพฤติกรรมคล้ายมนุษย์
ทำไมเราจึงต้องการการทดสอบทัวริง (Turing Test)
1. วัดประสิทธิภาพ AI ในการเลียนแบบมนุษย์ (Gauge Human-Like AI Performance):
หน้าที่หลักของการทดสอบทัวริงคือการประเมินความสามารถของ AI หรือ AGIในการตอบสนองที่ไม่สามารถแยกแยะได้จากการตอบสนองของมนุษย์ มาตรฐานนี้ช่วยให้นักพัฒนาสร้างระบบ AI ที่สามารถโต้ตอบกับมนุษย์ได้อย่างมีประสิทธิภาพ
2. ส่งเสริมความก้าวหน้าทาง AI (Promote Advancements in AI):
การทดสอบทัวริงกระตุ้นให้นักพัฒนาผลักดันขอบเขตของเทคโนโลยี AI ให้ก้าวไปข้างหน้า
การแข่งขันในการสร้าง AI ที่สามารถผ่านการทดสอบได้ช่วยผลักดันให้เกิดนวัตกรรมใหม่ ๆ เพื่อให้ AI แสดงความฉลาดที่คล้ายกับมนุษย์
3. รวบรวมข้อมูลเชิงลึกเกี่ยวกับความก้าวหน้าของ AI (Gather Insights on AI Progression):
การทดสอบทัวริงเป็นวิธีติดตามและประเมินความก้าวหน้าของ AI เมื่อเวลาผ่านไป
ผลลัพธ์ของการทดสอบแสดงให้เห็นทิศทางโดยรวมและความสำเร็จที่ได้รับในการวิจัยและพัฒนา AI
4. สร้างความน่าเชื่อถือให้กับ AI (Establish AI Credibility):
การแสดงให้เห็นว่า AI สามารถผ่านการทดสอบทัวริงได้ช่วยสร้างความน่าเชื่อถือ
การบรรลุมาตรฐานการจดจำและโต้ตอบภาษาที่คล้ายมนุษย์ช่วยเพิ่มความไว้วางใจและความเชื่อมั่นในความสามารถของระบบ AI
5. กระตุ้นการสนทนาเกี่ยวกับจริยธรรมของ AI (Fuel Conversations on AI Ethics):
เมื่อเทคโนโลยี AI ก้าวหน้าอย่างต่อเนื่อง คำถามเกี่ยวกับจริยธรรมของ AI และผลกระทบต่อชีวิตมนุษย์จะยิ่งมีความสำคัญ
หลังจากค้นคว้ามาหลายที่ จริง ๆ แล้ว การทดสองแนวคิดของ Alan Turing เป็นแนวคิดที่ไม่ได้ลงรายละเอียดในกระบวน ทดสอบทัวริง (Turing Test) จริงๆ เพราะการทำสอบควรระบุความเหมาะสมในการทดสอบ และมาตรฐาน เพื่อความสมบูรณ์ในการทดสอบ ซึ่งมีนักวิชาการด้าน AI และคอมพิวเตอร์ มาตีความและขยายความจากแนวความคิดนี้เพื่อให้เป็นมาตรฐานในการวัด AGI แนวความคิด “เกมส์เลียนแบบ” ของบิดาคอมพิวเตอร์
อลัน ทัวริง (1912–1954) ได้ตีพิมพ์บทความในวารสาร Mind ชื่อ “Computing Machinery and Intelligence” ในบทความนี้ ทัวริงได้ตั้งคำถามที่สำคัญที่สุดคำถามหนึ่งในประวัติศาสตร์วิทยาศาสตร์ว่า “เครื่องจักรสามารถคิดได้หรือไม่?” เป็นแนวคิดที่ตรงไปตรงมาเพียงพอที่จะทดสอบความสามารถของ AI / AGI ว่า จากคำถามตั้งต้นเดิม เครื่องจักรสามารถทำงานทางความรู้ความเข้าใจได้เหมือนกับสมองของมนุษย์ ซึ่ง “เกมส์เลียนแบบ” มีพื้นฐานแนวคิดเหมาะสม
มีความเชื่อกันว่า ถ้า AI สามารถผ่านมาตรฐาน ทดสอบทัวริง (Turing Test) นี้ได้ มนุษยชาติจะเข้าสู่ Epoch ถัดไปของอนาคต ซึ่งมีการพยากรณ์ว่าจะเกิดขึ้นในปี 2029 ครับ
ส่วนขยายความสำคัญ
อ้างอิง : Turing Test / AlanTuring.net
- นิยาม ของ AGI
ปัญญาประดิษฐ์ทั่วไป (Artificial General Intelligence – AGI) หมายถึงระบบปัญญาประดิษฐ์ที่มีความสามารถในการทำงานทางปัญญาได้หลากหลายเทียบเท่าหรือเหนือกว่ามนุษย์ ซึ่งแตกต่างจากปัญญาประดิษฐ์เฉพาะทาง (Artificial Narrow Intelligence – ANI) ที่ถูกออกแบบมาเพื่อทำงานเฉพาะด้านเท่านั้น
นิยามจากแหล่งต่าง ๆ:
วิกิพีเดียภาษาไทย: AGI คือระบบเครื่องจักรที่สามารถทำงานได้อย่างชาญฉลาดเทียบเท่ามนุษย์ และเป็นเป้าหมายหลักของงานวิจัยด้านปัญญาประดิษฐ์ th.wikipedia.org
IBM: AGI เป็นขั้นตอนสมมุติในพัฒนาการของการเรียนรู้ของเครื่อง (Machine Learning) ที่ระบบ AI สามารถเทียบเคียงหรือเกินความสามารถทางปัญญาของมนุษย์ในทุกงาน ibm.com
TechTarget: AGI คือการแทนความสามารถทางปัญญาทั่วไปของมนุษย์ในซอฟต์แวร์ เพื่อให้ระบบสามารถหาวิธีแก้ปัญหาในงานที่ไม่เคยพบมาก่อน techtarget.com
Gartner: AGI เป็นรูปแบบของ AI ที่มีความสามารถในการเข้าใจ เรียนรู้ และประยุกต์ใช้ความรู้ในงานและโดเมนที่หลากหลาย gartner.com
วิกิพีเดียภาษาอังกฤษ: AGI หมายถึงระบบ AI ที่สามารถทำงานทางปัญญาได้หลากหลายเทียบเท่ามนุษย์ ซึ่งแตกต่างจาก AI เฉพาะทางที่จำกัดอยู่ในงานเฉพาะ en.wikipedia.org
ปัจจุบัน AGI ยังคงเป็นแนวคิดที่อยู่ในขั้นตอนการวิจัยและพัฒนา และยังไม่มีระบบใดที่สามารถถือว่าเป็น AGI ได้อย่างแท้จริง
↩︎ - GLUE (General Language Understanding Evaluation) เป็นมาตรฐานที่ใช้ในการประเมินความสามารถของโมเดลปัญญาประดิษฐ์ด้านการประมวลผลภาษาธรรมชาติ (Natural Language Processing – NLP) โดยมุ่งเน้นการทดสอบความเข้าใจภาษาของโมเดลในหลายๆ งานพร้อมกัน เพื่อให้ได้ภาพรวมของประสิทธิภาพและความสามารถในการทั่วไปของโมเดล
รายละเอียดของ GLUE:
ชุดข้อมูลหลายงาน (Multi-Task Benchmark): GLUE ประกอบด้วยชุดข้อมูลจากงานต่างๆ ในด้าน NLP เช่น การวิเคราะห์ความรู้สึก (Sentiment Analysis), การอนุมานเชิงตรรกะ (Logical Inference), และการจับคู่ความหมายของประโยค (Paraphrase Detection) เป็นต้น
การวิเคราะห์เชิงลึก (Diagnostic Test Suite): นอกจากการประเมินทั่วไปแล้ว GLUE ยังมีชุดทดสอบที่ออกแบบมาเพื่อวิเคราะห์ความสามารถของโมเดลในด้านภาษาศาสตร์เฉพาะด้าน เช่น ไวยากรณ์ ความหมาย และการใช้ภาษาในบริบทต่างๆ
การส่งเสริมการเรียนรู้ข้ามงาน (Cross-Task Learning): เนื่องจากบางงานใน GLUE มีข้อมูลการฝึกสอนจำกัด การใช้ GLUE ช่วยส่งเสริมให้โมเดลสามารถเรียนรู้และแบ่งปันความรู้ระหว่างงานต่างๆ เพื่อเพิ่มประสิทธิภาพโดยรวม
GLUE ได้รับการนำเสนอครั้งแรกในงานวิจัย “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding” โดย Alex Wang และคณะ ในปี 2018 arxiv.org
ปัจจุบัน GLUE ถือเป็นมาตรฐานสำคัญในการประเมินโมเดล NLP และมีการพัฒนาต่อยอดเป็น SuperGLUE ซึ่งเป็นเวอร์ชันที่ยากขึ้น เพื่อทดสอบความสามารถของโมเดลในระดับที่สูงขึ้น
↩︎ - SuperGLUE (Super General Language Understanding Evaluation) เป็นมาตรฐานที่พัฒนาต่อยอดจาก GLUE เพื่อประเมินความสามารถของโมเดลปัญญาประดิษฐ์ด้านการประมวลผลภาษาธรรมชาติ (NLP) ในงานที่ซับซ้อนและท้าทายมากขึ้น
ความแตกต่างที่สำคัญระหว่าง SuperGLUE และ GLUE:
ความท้าทายที่เพิ่มขึ้น: SuperGLUE ประกอบด้วยชุดงานที่ยากขึ้นเมื่อเทียบกับ GLUE เพื่อทดสอบความสามารถของโมเดลในด้านการเข้าใจภาษาอย่างลึกซึ้ง
ความหลากหลายของรูปแบบงาน: นอกจากการจำแนกประโยคและคู่ประโยคแล้ว SuperGLUE ยังรวมงานที่เกี่ยวข้องกับการระบุการอ้างอิงร่วม (coreference resolution) และการตอบคำถาม (question answering)
เกณฑ์มาตรฐานของมนุษย์ที่ครอบคลุม: SuperGLUE มีการประเมินประสิทธิภาพของมนุษย์ในทุกงาน เพื่อเปรียบเทียบกับโมเดล AI และระบุช่องว่างที่ยังต้องพัฒนา
การสนับสนุนด้านโค้ดที่ปรับปรุง: SuperGLUE มาพร้อมกับเครื่องมือที่ช่วยในการฝึกอบรมและประเมินผลโมเดล NLP อย่างมีประสิทธิภาพ
กฎการใช้งานที่ปรับปรุง: มีการปรับปรุงเงื่อนไขสำหรับการเข้าร่วมในตารางผู้นำของ SuperGLUE เพื่อให้การแข่งขันเป็นธรรมและให้เครดิตแกผู้สร้างข้อมูลและงานอย่างเต็มที่
arxiv.org
งานที่รวมอยู่ใน SuperGLUE:
➡️ BoolQ: การตอบคำถามแบบใช่/ไม่ใช่จากบทความ Wikipedia
➡️ CommitmentBank (CB): การประเมินระดับความมั่นใจของผู้เขียนต่อความจริงของประโยค
➡️ Choice of Plausible Alternatives (COPA): การเลือกสาเหตุหรือผลลัพธ์ที่เป็นไปได้มากที่สุดสำหรับสถานการณ์ที่กำหนด
➡️ Multi-Sentence Reading Comprehension (MultiRC): การตอบคำถามที่ต้องการการสรุปข้อมูลจากหลายประโยค
➡️ Reading Comprehension with Commonsense Reasoning Dataset (ReCoRD): การเติมคำในช่องว่างที่ต้องใช้ความเข้าใจและเหตุผลทั่วไป
➡️ Recognizing Textual Entailment (RTE): การพิจารณาว่าประโยคหนึ่งสรุปหรือขัดแย้งกับอีกประโยคหนึ่ง
➡️ Word-in-Context (WiC): การตัดสินว่าคำเดียวกันในสองบริบทมีความหมายเหมือนกันหรือไม่
➡️ Winograd Schema Challenge (WSC): การระบุการอ้างอิงของสรรพนามในประโยคที่ซับซ้อน
SuperGLUE ได้รับการยอมรับอย่างกว้างขวางในชุมชนวิจัย NLP และมีการใช้เป็นเกณฑ์มาตรฐานในการประเมินโมเดลภาษาขนาดใหญ่ (LLMs) อย่างต่อเนื่อง deepgram.com ↩︎ - SQuAD (Stanford Question Answering Dataset) เป็นชุดข้อมูลที่พัฒนาโดยมหาวิทยาลัยสแตนฟอร์ด เพื่อใช้ในการประเมินความสามารถของโมเดลปัญญาประดิษฐ์ด้านการทำความเข้าใจและตอบคำถามจากข้อความที่กำหนด ชุดข้อมูลนี้ประกอบด้วยคำถามมากกว่า 100,000 ข้อ ซึ่งถูกสร้างขึ้นโดยผู้ใช้ทั่วไปบนบทความจากวิกิพีเดีย โดยคำตอบของแต่ละคำถามจะเป็นส่วนหนึ่งของข้อความในบทความที่เกี่ยวข้อง
arxiv.org
คุณสมบัติที่สำคัญของ SQuAD:
➡️ ความหลากหลายของคำถาม: คำถามใน SQuAD ครอบคลุมหัวข้อต่าง ๆ อย่างกว้างขวาง ตั้งแต่ประวัติศาสตร์ วิทยาศาสตร์ วัฒนธรรม และอื่น ๆ
➡️ การตอบคำถามจากบริบท: โมเดลต้องสามารถระบุและดึงข้อมูลที่เกี่ยวข้องจากบทความเพื่อสร้างคำตอบที่ถูกต้อง
➡️ การประเมินประสิทธิภาพของโมเดล: SQuAD ถูกใช้เป็นมาตรฐานในการวัดความสามารถของโมเดล NLP ในการทำความเข้าใจและตอบคำถามจากข้อความ
SQuAD ได้กลายเป็นมาตรฐานสำคัญในการประเมินความสามารถของโมเดล NLP และมีการพัฒนาต่อยอดเป็น SQuAD 2.0 ซึ่งเพิ่มความท้าทายด้วยการรวมคำถามที่ไม่มีคำตอบในบทความ เพื่อทดสอบความสามารถของโมเดลในการระบุว่าคำถามใดไม่มีคำตอบที่ชัดเจน ↩︎