

{kind=link}
รู้สึกอย่างไรเมื่อความเชื่อถูกพังลงกันครับ ความรู้สึกโหวง ๆ ในท้อง แล้วเราก็ใช้เวลาพักนึงปรับความรู้สึกและกลับมาตั้งคำถามกับความคิดตัวเองที่ถูกพังทลายลง นั่นคือสิ่งที่เกิดขึ้นกับตลาด AI ในเดือนมกราคมปี 2025 ต้อนรับการรับตำแหน่งของประธานาธิบดีคนใหม่ แม้ Donald Trump จะไม่ได้แสดงอาการอะไรมาก แต่คงรู้สึกบ้างไม่น้อยที่จีนสามารถขึ้นมาเป็นคู่แข่งที่น่ากลัวได้ในระยะเวลาแค่ 2 ปีDeepSeek R1
เว็บนี้พยายามจะไม่เป็นเว็บข่าว แต่ก็เลี่ยงไม่ได้ที่เราจะเขียนถึงเรื่องที่น่าตื่นเต้น และอยู่ในกระแส ผมจะเขียนบทความนี้ยาว ๆ เพื่อเล่าสิ่งที่เกิดขึ้นภายใต้ความลับของ DeepSeek แบบ Geek Geek ให้ฟังไปพร้อม ๆ กับมุมมองธุรกิจ รวบรวมจากแหล่งข้อมูลวิเคราะห์จากหลายแหล่งสรุปมาไว้ด้วยกันDeepSeek R1
อะไรวัดว่าใครคือ ตัวจริงในโลก AI
เวลามีข่าวว่า มีการพัฒนาโมเดล AI ในมิติลึก ๆ จริง ๆ มีหลายแขนงของ AI Definition มาก ๆ ครับ เวลาเราพูดแบบนี้เพราะคำว่า AI เป็นคำใหญ่ ทั้งกว้าง และลึกได้ แต่ในยุค ChatGPT นั้นเรามุ่งเป้าไปที่โมเดลขนาดใหญ่ LLMs (Large Language Model) เพราะว่า Model เหล่านี้มีความซับซ้อนมาก ทั้งในการพัฒนา และความสามารถในการให้ผลลัพธ์ ความซับซ้อน จากจำนวนพารามิเตอร์ที่มีจำนวนมากในการ Trained AI ที่ทำให้ AI สามารถสร้างความคิดได้แบบมนุษย์ ทั้งตรรกะ ความสามารถทางภาษา คณิตศาสตร์ Common Sense ทำให้การตอบคำถามไม่ใช่แค่การให้คำตอบแบบทั่วไปที่เราเห็นมาก่อน อันนี้ทุกคนคงเห็นวิวัฒนาการมากขึ้นได้เองแล้ว
แล้วเราจะรู้ว่าใครพัฒนา LLMs ได้เก่งกว่ากัน ในวงการ AI เราก็จะมี Benchmark เอาไว้วัดความสามารถที่เป็นฐานที่เราจะให้การยอมรับ มองความสามารถในการแก้ไขโจทย์ปัญหาที่ซับซ้อน ดูว่า Resolved Rate สามารถทำได้สูงเป็นกี่เปอร์เซ็นต์ หรือเอา AI ไปทดสอบมาตรฐานต่าง ๆ ที่เอาไว้วัดความสามารถเหมือนที่มนุษย์ต้องวัดความสามารถกัน เช่น ทางการแพทย์ เป็นหมอ โมเดล MedLM LLM ทางการแพทย์ ก็ทักจะวัด USMLE The USMLE®, or the United States Medical Licensing Examination ลองสอบมาตรฐานแพทย์ดู ก็จะเห็นความเก่งของโมเดลที่ทำคะแนนได้ต่างกัน
DeepSeek R1 ก็ถูกเอาไปทดสอบความสามารถเช่นกัน ต้นทางจากเว็บ Huggingface.co แสดงการทดสอบ 6 การวัดสำคัญ AIME 20241 , Codeforces2 , GPQA Diamond3 , MATH-5004 , MMLU5, SWE-bench Verified6 ซึ่งจากกราฟเปรียบเทียบความสามารถ DeepSeek-R1, DeepSeek-R1-32B ซึ่งเอามาเปรียบเทียบกับ Model o1-1217 และ o1-mini ของ OpenAI อย่างชัดเจน และความสามารถ DeepSeek R1 เอาชนะได้ 3 การทดสอบ และที่ได้คะแนนน้อยกว่าก็ต่างกันเพียงเล็กน้อยเท่านั้นDeepSeek R1
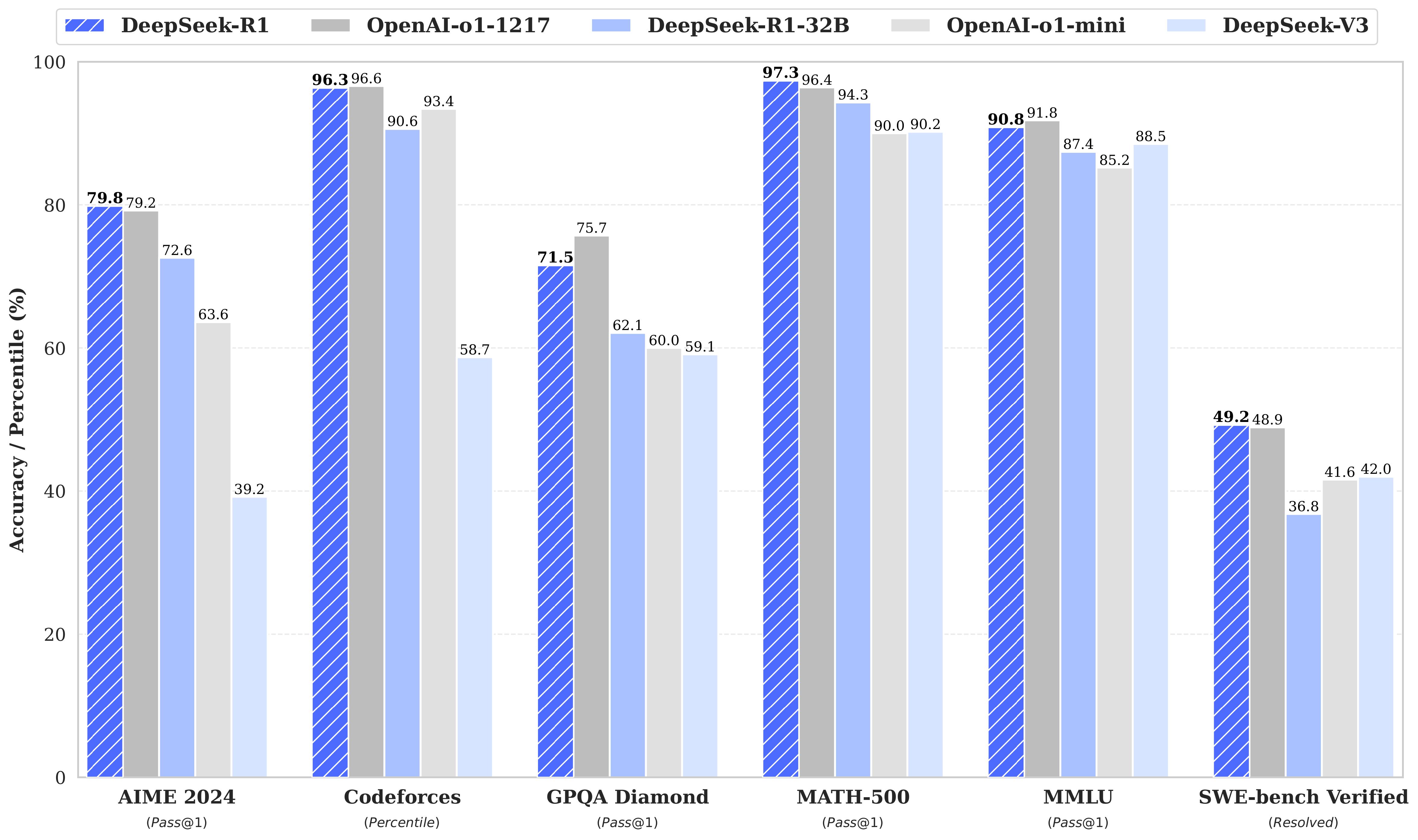
ความเก่งของ DeepSeek R1 เหมือนม้ามืดที่วิ่งเข้าเส้นชัยแบบที่ไม่มีใครคาดมาก่อน และสิ่งที่ตามมาคือ ความหวาดหวั่นของนักลงทุน
ตลาดหุ้น Tech สหรัฐปรับลดลง ตลาดชิป ที่เป็นหุ้นน่าจับตาในยุค AI ที่ทำจุดสูงสุดหลายครั้งก็ลดลงตาม ๆ กัน โดยเฉพาะ NVIDIA ราคาหุ้นลดลงถึง 16.97% มีบทวิเคราะห์ที่เขียนไปก่อนหน้านี้แล้ว จากความเห็นของ Andrew Ng ต่อการมาของ DeepSeek บทความนี้จะเห็นความคิดมุมมองผลกระทบจากคนวงใน
แค่เก่งกว่าก็ไม่ใช่เรื่องที่เดียวที่ทำให้น่ากลัว
นอกจากเรื่องความเก่งแล้ว อันที่สร้างความวิตกอย่างมาก คือ ต้นทุนของการฝึกโมเดล ตามข้อมูลจากข่าว ต้นทุนที่ใช้ในการฝึกโมเดล DeepSeek R1 คือ 5.6 ล้านดอลลาร์ ประมาณ 196 ล้านบาท ซึ่งตัวเลขของต้นทุน ที่ผมพูดเสมอ ๆ ในการเทรนนิ่ง หรือให้ข้อมูลลูกค้า คือ ขั้นต่ำในการฝึกโมเดลต้องใช้เงิน 100 ล้านดอลลาร์ หรืออาจจะมากกว่านั้น การที่พูดตัวเลขนี้ ทำให้ผมพูดเสมอ ๆ ว่า คนที่สามารถการลงทุนใช้เงินในการฝึกโมเดลแบบนี้ได้ ทุก ๆ ปีก็จะเกิดขึ้นในบริษัท Big Tech เท่านั้น ใครจะมีเงินถุงเงินถังทำแบบนี้ได้ไม่มีทางเลย ในฐานะบริษัทเทครายเล็ก ๆ หรือลูกค้าจะระดับ Corp หรือ Enterprise การใช้บริการโมเดลจาก Technology Provider คุ้มค่ามากกว่า
ผมเห็นข่าวหลาย ๆ โครงการของภาครัฐ พยายามให้เงินทุนสนับสนุน แต่หากเงินสนับสนุนไม่ได้อย่างต่อเนื่อง โมเดลก็จะไม่โต เชิงความสามารถ และการคงการใช้งานในระยะยาวอยู่ดี กลายเป็นโมเดลล้าสมัยหรือ ยังมีช่องว่างของการพัฒนาด้านเหตุผล หรือด้านอื่น ๆ อีก ความสำคัญในการพัฒนาฝึก โมเดลในระยะหลัง Model ถูกให้ความสำคัญกับให้ AI มี reasoning model ฝึกให้ AI คิดแบบมีเหตุผล ที่ดีขึ้นไปเรื่อย ๆ
การตัดสินใจอันนี้ขึ้นอยู่กับวัตถุประสงค์ระยะสั้น ระยะยาวในการออกแบบโครงการประกอบครับ ถ้าท้ายสุดเป้าหมายคือการพา AI ไปถึงระดับ AGI ยังมีความท้าทายอีกมากในการพา AI พัฒนาไปถึงจุดที่เป็น AGI ที่สมบูรณ์ ถ้าสนใจว่าเมื่อไหร่ลองอ่านอันนี้นะครับ
กลับมาที่ความเชื่อเรื่อง ต้นทุนของการฝึกโมเดล นี้ DeepSeek ทำให้เห็นว่า โมเดลที่เก่ง ไม่ต้องพึ่งพา ทรัพยากรชิปขั้นสูง ก็พัฒนาความสามารถเทียบเท่าคู่แข่งรายสำคัญได้
การถูกจำกัด จำกัดทรัพยากรชิปขั้นสูง ไม่ว่าจะด้วยนโยบายกีดกัน หรือต้นทุนที่จำกัด ก็บีบให้นักพัฒนาต้องหาหนทางในการลดช่องว่างข้อจำกัดนี้ จึงเกิดโจทย์การทำงานบนฮาร์ดแวร์ที่มีข้อจำกัด รีดประสิทธิภาพให้ได้มากที่สุด
การได้ AI ที่เก่ง โดยมีข้อจำกัดด้านทรัพยากรเป็นความน่ากลัวของคู่แข่ง และการเปลี่ยนข้อจำกัด เป็นโจทย์ ที่ถูกแก้ได้ นั่นทำให้ความเก่งในการทำวิศวกรรมปัญญาประดิษฐ์ จะมีแนวทางใหม่ ๆ ที่อาจเกิดขึ้นได้อีก
เข้าใจเรื่อง DeepSeek R1 ให้ถูกก่อน ข่าวผิด ๆ เยอะ
เอาเรื่องที่ทุกคนเข้าใจผิดจากข่าวจากโพสต์ของ Philipp Schimid Technical Lead & LLMs at Hugging Face ออกมาโพสต์เองว่าข่าวที่กระจายออกไปมีความเข้าใจผิดอย่างมาก
No, the training didn’t cost only ~$6M dollars; the compute for the base model (no RL) was equivalent to GPU hours worth $5.5M, excluding ablations, smaller runs, data generation, and any of DeepSeek R1 training.
ไม่ใช่เลย ต้นทุนการฝึกไม่ได้มีเพียง ~$6 ล้านดอลลาร์ ต้นทุนการประมวลผลสำหรับโมเดลพื้นฐาน (ที่ยังไม่มีการใช้ RL) อยู่ที่ประมาณ $5.5 ล้านดอลลาร์ ยังไม่รวมการทดลองย่อย (ablations) การรันแบบขนาดเล็ก การสร้างข้อมูล และการฝึกเพิ่มเติมอื่น ๆ สำหรับ DeepSeek R1
ตัวเลข $5.5 ล้านดอลลาร์ ค่าใช้จ่ายนี้หมายถึงต้นทุนคำนวณ (Compute Costs) ของโมเดลฐาน (Base Model) ซึ่งเป็นหนึ่งในต้นทุนหลักของการฝึกโมเดล AI ขนาดใหญ่ ค่าใช้จ่ายนี้ยังไม่รวมถึงการทดลองเพื่อทดสอบแนวทางใหม่ ๆ ที่มักทำก่อนการฝึกจริง ค่าใช้จ่ายที่ยังไม่นำมารวม เช่น
- Ablation Studies (การทดลองแยกองค์ประกอบ) ทดสอบความสำคัญของส่วนประกอบต่าง ๆ เช่น Reward Models หรือ Language Consistency เป็นขั้นตอนสำคัญก่อนตัดสินใจเลือกอัลกอริทึมสุดท้าย
- การรันงานขนาดเล็ก (smaller runs)
- การสร้างข้อมูล (data generation) ข้อมูลที่ใช้ในการฝึกโมเดลมักมาจาก การสร้างข้อมูลสังเคราะห์ (Synthetic Data)
- การฝึกขั้นตอน RL ทั้งหมดของ DeepSeek R1
- Infrastructure & Operational Costs (ค่าโครงสร้างพื้นฐานและการจัดการ): ค่าใช้จ่ายด้านเซิร์ฟเวอร์, พนักงานวิจัย, การจัดการข้อมูล ฯลฯ
ต้นทุน รวมจริง อาจสูงกว่า $6M อย่างมีนัยสำคัญ
No, it’s not a side project (maybe started as one). DeepSeek is backed and owned by High-Flyer, a Chinese hedge fund; in 2020, they managed assets of over 7 billion dollars, and their talent includes Olympic medalists in mathematics, physics, and informatics.
หลายแหล่งข่าวบอกว่า เป็น Side Project แต่ DeepSeek ได้รับการสนับสนุนและเป็นเจ้าของโดย High-Flyer ซึ่งเป็นกองทุนเฮดจ์ฟันด์จากจีน ในปี 2020 พวกเขาบริหารสินทรัพย์มูลค่ากว่า 7 พันล้านดอลลาร์ และมีทีมงานที่ประกอบด้วยผู้ได้รับเหรียญโอลิมปิกในสาขาคณิตศาสตร์ ฟิสิกส์ และสารสนเทศ จึงจะบอกว่า DeepSeek มันใหญ่กว่าที่คิด และจริงจังมาก
No, they don’t just have a few GPUs. They have ~50k GPUs.
ไม่ใช่แค่ว่าพวกเขามี GPU เพียงไม่กี่ตัว พวกเขามี GPU ประมาณ 50,000 ตัว (น้อยซะที่ไหนล่ะ)
The real Deepseek R1 is 671B MoE model that needs > 16x 80GB Memory (16x H100s).
DeepSeek R1 ตัวจริงเป็นโมเดลขนาด 671 พันล้านพารามิเตอร์แบบ Mixture-of-Experts (MoE) ที่ต้องการหน่วยความจำมากกว่า 16 ตัวของ GPU H100 ขนาด 80GB
Yes, the Deepseek R1 671B is really good! And they do great open source and science work > 2 years already.
ใช่แล้ว DeepSeek R1 ขนาด 671 พันล้านพารามิเตอร์มีประสิทธิภาพสูงมาก! และพวกเขาได้ทำงานโอเพนซอร์สและวิจัยทางวิทยาศาสตร์มาแล้วกว่า 2 ปี
There are 6 “distilled” versions. They are fine-tuned Qwen and Llama on 800k samples, (NO RL). That’s not “R1”. The smallest one with 1.5B (Yes, you can run locally, but it’s not near R1).
มีเวอร์ชัน “distilled” จำนวน 6 เวอร์ชัน ซึ่งเป็นการปรับแต่งโมเดล Qwen และ Llama ด้วยข้อมูล 800,000 ตัวอย่าง (ไม่มีการใช้ RL) ดังนั้นนี่ไม่ใช่ “R1” ตัวจริง โมเดลขนาดเล็กสุดมีพารามิเตอร์ 1.5 พันล้าน (ใช่ คุณสามารถรันได้ในเครื่องของคุณเอง แต่ประสิทธิภาพยังห่างไกลจาก R1 ตัวจริง)
คือ จะบอกว่าพวก เวอร์ชันที่พารามิเตอร์สูง ๆ 1.5 พันล้าน แม้จะรันได้ในเครื่องของคุณเอง นั้นไม่ได้มีประสิทธิภาพ ถ้าจะใช้ก็ไปเป็น R1 เท่านั้นอย่างหลงไป Version “distilled”
Yes, the hosted version on chat(.)deepseek(.)com might use your data to train new models (as per ToS of DS).
ใช่แล้ว เวอร์ชันที่ให้บริการผ่านเว็บไซต์ chat(.)deepseek(.)com อาจใช้ข้อมูลของคุณเพื่อฝึกโมเดลใหม่ ตามเงื่อนไขการให้บริการ (ToS) ของ DeepSeek
ทำไม ต้นทุนของการฝึกโมเดล นี้ DeepSeek R1 ถึงถูก
ส่วนนี้ค่อนข้าง Geek ถ้าเป็นสาย Biz ก็ข้ามส่วนนี้ไปอ่านส่วนสรุปได้เลยครับ
ผมขออ้างอิงแหล่งศึกษาหลายแหล่งนะครับ เนื่องจากไม่ใช่นักพัฒนาโดยตรง เพียงแค่ทำธุรกิจและอยู่ในแวดวง AI เท่านั้น อ้างอิงจาก นักพัฒนาเขียนบทความ จากที่ควานอ่านหลาย ๆ ที่ผมขอยึดความเห็นและคำอธิบายของ Philipp Schimid เป็นหลักและอาจเสริมส่วนความเห็นจากเว็บ และ Community ของนักพัฒนา LLM อื่น ๆ เข้ามา
เทคนิคที่ถูกนำมาใช้ คือการปรับปรุงอัลกอริทึมเดิมที่ชื่อว่า Proximal Policy Optimization (PPO) ซึ่ง OpenAI พัฒนาขึ้นมาเพื่อแก้ไขความไม่เสถียรของการฝึกโมเดล เป็นการฝึกโมเดลแบบ Reinforcement Learning ให้มีความเสถียรและมีประสิทธิผลมากขึ้น
หลังจากได้ Foundation Model โมเดลพื้นฐาน สิ่งที่เราต้องทำต่อคือการฝึกให้ AI สามารถทำงานได้อย่างมีคุณภาพ การฝึกให้ AI ทำการงานให้มีคุณภาพเราจะใช้วิธีการ Reinforcement Learning (RL)7 ฝึกให้ Agent ฉลาดขึ้นต่อการรับมือกับสถานการณ์สภาพแวดล้อมที่แตกต่างกัน การฝึกนี้เป็นการดูการเรียนรู้การตัดสินใจของ AI แล้วให้รางวัลตอบแทน และบทลงโทษ กับผลของการทำครั้งนั้น ๆ ของ AI
ซึ่งปัญหาความไม่เสถียรการฝึก RL อยู่ที่การให้รางวัลและบทลงโทษที่ไม่สม่ำเสมอ หรือมีการเปลี่ยนแปลงบ่อยครั้ง เช่น การให้หุ่นยนต์เดินในภาพแวดล้อมที่เปลี่ยนแปลงตลอดเวลา ทำให้หุ่นยนต์นั้นเรียนรู้ได้ยาก โมเดลไม่สามารถปรับตัวได้ทันการเปลี่ยนแปลง
ซึ่ง Proximal Policy Optimization (PPO) เป็นอัลกอริทึมหลักที่ปรับปรุงความเสถียรของการเรียนรู้ของ AI ด้วย RL ที่ไม่ให้มีการเปลี่ยนแปลงนโยบายมากเกินไป โดยในทุกครั้งจะมีการเทียบนโยบายเก่าและใหม่ และจัดการให้นโยบายไม่ให้มีการเปลี่ยนแปลงมากเกินไป การเรียนของ AI จะเสถียรมากขึ้น ซึ่ง GRPO (Group Relative Policy Optimization) จะเป็นอัลกอริทึม ถูกพัฒนาขึ้นเพื่อแก้ไขข้อจำกัดบางประการของ PPO ทั้งสองอัลกอริทึมใช้ KL Divergence Penalty เพื่อป้องกันไม่ให้โมเดลเปลี่ยนนโยบาย (Policy) มากเกินไป
ในตัว DeepSeekMath ได้นำหลักการ GRPO นี้มาใช้ เพื่อสอน LLMs ในบริบทของการให้เหตุผลทางคณิตศาสตร์แต่ยอดให้ดีมากยิ่งขึ้น ด้วยกำหนดการให้รางวัลที่มาจากกฎเกณฑ์ (rule-based)การแก้โจทย์คณิตศาสตร์: หากคำตอบถูกต้องให้ 1 คะแนน ถ้าผิดให้ 0 คะแนน หรือแบบทวิภาค (binary-based) คือการให้รางวัลเป็นระดับชัดเจนว่า ดีหรือไม่ดี รวมถึงโมเดลรางวัลทั่วไป (General Reward Models) Chatbot ด้านบริการลูกค้า: ให้คะแนน 1-7 ตามระดับความสุภาพและความช่วยเหลือ
เพื่อปรับปรุงโมเดลให้มีความช่วยเหลือที่ดีขึ้น (helpfulness)
| ประเภท | ความยากง่าย | ความแม่นยำ | ความยืดหยุ่น |
|---|---|---|---|
| Rule-based | ง่าย | สูง (ถ้ามีกฎชัดเจน) | ต่ำ |
| Binary-based | ง่ายมาก | สูงในงานที่ชัดเจน | ต่ำ |
| General Reward Models | ปานกลาง – ยาก | ปานกลาง-สูง (ขึ้นกับโมเดล) | สูง |
ตัวอย่างการใช้งานใน LLM General Reward Models: ใช้โมเดลที่ฝึกให้ประเมินระดับความชัดเจนและความสร้างสรรค์
- สอนให้โมเดลแก้โจทย์คณิตศาสตร์ Rule-based: ตรวจคำตอบว่าใช่/ไม่ใช่
- สอนให้โมเดลเขียนข้อความสุภาพ Binary-based: สุภาพ/ไม่สุภาพ
- สอนให้โมเดลเขียนบทความที่อ่านง่าย General Reward Models: ใช้โมเดลที่ฝึกให้ประเมินระดับความชัดเจนและความสร้างสรรค์

ขั้นตอนการทำงานของ GRPO
- Sampling (การสุ่มตัวอย่าง)
โมเดลจะสร้างคำตอบหลายชุดสำหรับแต่ละคำสั่ง (prompt) โดยใช้พฤติกรรมปัจจุบันของโมเดล (current policy) - Reward Scoring (การให้คะแนนรางวัล)
คำตอบแต่ละชุดจะได้รับคะแนนจากฟังก์ชันรางวัล (reward function) ซึ่งอาจใช้เกณฑ์จากกฎ (rule-based) หรือผลลัพธ์ที่ได้ (outcome-based) - Advantage Calculation (การคำนวณความได้เปรียบ)
GRPO จะคำนวณค่าเฉลี่ยของรางวัลที่ได้จากกลุ่มเป็นค่าฐาน (baseline) จากนั้นคำนวณความได้เปรียบ (advantage) ของคำตอบแต่ละชุด โดยเปรียบเทียบกับค่าเฉลี่ยนี้ และมีการปรับคะแนนให้อยู่ในช่วงที่เหมาะสม (normalized) - Policy Optimization (การปรับปรุงนโยบาย)
โมเดลจะถูกฝึกเพื่อเพิ่มค่าสมการวัตถุประสงค์ของ GRPO โดยใช้ความได้เปรียบที่คำนวณได้และเทอม KL divergence ซึ่งใน GRPO เทอมนี้จะถูกจัดการต่างจาก PPO โดย PPO จะใส่ KL ลงในฟังก์ชันรางวัล ในขณะที่ GRPO จะใส่ KL ลงในสมการวัตถุประสงค์โดยตรง
GRPO ถือเป็นความก้าวหน้าสำคัญในการพัฒนาความสามารถด้านการให้เหตุผลเชิงตรรกะของโมเดลภาษา โดยลดต้นทุนการคำนวณและเพิ่มความยืดหยุ่นในการฝึกโมเดลอย่างมีประสิทธิภาพ
Exhibit: Pure Reinforcement Learning (R1-zero)
การพัฒนา DeepSeek R1 เป็นผลลัพธ์จากการทดลองใช้ Reinforcement Learning (RL) กับโมเดลพื้นฐานของทีม โดยพวกเขาได้ใช้ GRPO (Group Relative Policy Optimization) ในการปรับปรุงความสามารถในการให้เหตุผลเชิงข้อความแบบไม่มีการกำกับดูแล (unsupervised reasoning text completions)
การฝึกนี้ใช้ Rule-based Reward Models ที่ออกแบบมาเพื่อเน้นการพัฒนาด้านต่างๆ เช่น:
- Accuracy Rewards (รางวัลความถูกต้อง) ตรวจสอบว่าคำตอบถูกต้องหรือไม่ ใช้ในงานที่คำตอบถูก-ผิดอย่างชัดเจน เช่น คณิตศาสตร์ หรือการแก้โจทย์เขียนโค้ด
- Format Rewards (รางวัลความถูกต้องของรูปแบบ) โมเดลจะถูกฝึกให้ใส่กระบวนการคิด (reasoning process) ระหว่างแท็ก ‘’ และ ‘’ หากโมเดลเขียนขั้นตอนการคิดใน ‘’ และ ‘’: +1 หากข้ามขั้นตอน หรือไม่มีการจัดรูปแบบที่ถูกต้อง: 0 ใช้พัฒนา Chain-of-Thought (CoT) reasoning ให้โมเดลสามารถอธิบายกระบวนการคิดได้ชัดเจน
ทีม DeepSeek ได้นำ GRPO มาปรับใช้กับงานการให้เหตุผลแบบไม่มีการกำกับดูแล โดยใช้โมเดลรางวัลตามกฎ (Rule-based) ที่เน้น ความถูกต้อง (Accuracy) และ รูปแบบการนำเสนอ (Format) ซึ่งช่วยพัฒนาโมเดลให้สามารถ:
- คิดคำนวณได้แม่นยำ
- อธิบายเหตุผลได้อย่างเป็นระบบ
นี่คือแนวทางการใช้ Reinforcement Learning ในการพัฒนาความสามารถของโมเดลภาษาขนาดใหญ่ (LLM) อย่างเป็นรูปธรรม ผลลัพธ์จากการนำ GRPO (Group Relative Policy Optimization) และ Rule-based Reward Models มาใช้กับ DeepSeek R1 ทำให้ประสิทธิภาพของโมเดลเพิ่มขึ้นอย่างมีนัยสำคัญ โดยเฉพาะอย่างยิ่งกับการทดสอบ AIME 2024 (American Invitational Mathematics Examination)
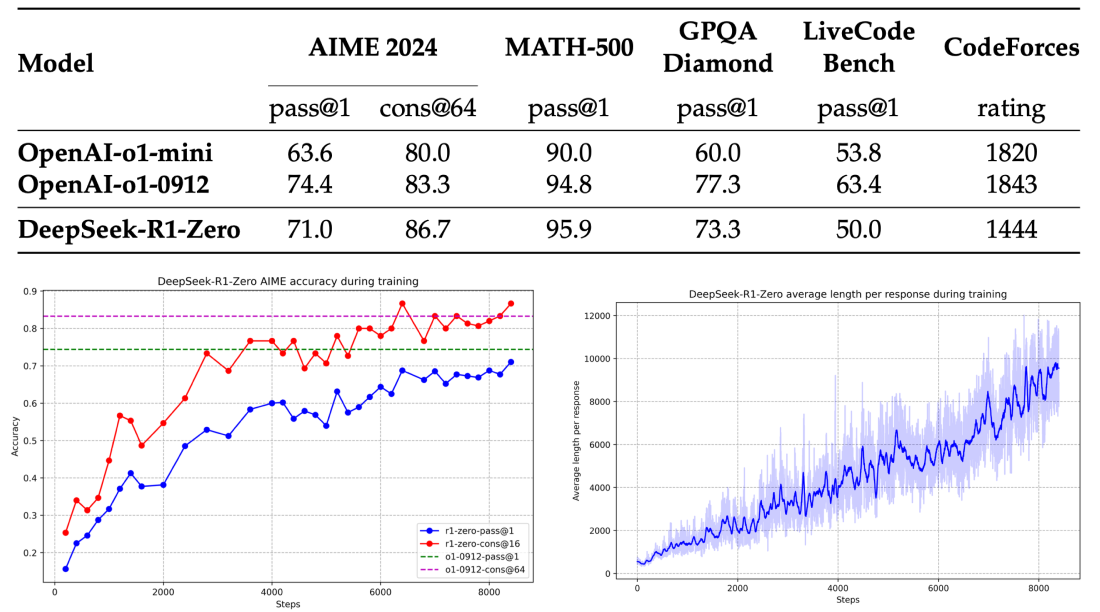
คะแนน pass@1 (ความแม่นยำของคำตอบที่ถูกต้องตั้งแต่ความพยายามแรก)
เพิ่มขึ้นจาก 15.6% → 71.0% 🎯
ประสิทธิภาพ เทียบเท่ากับโมเดล OpenAI-o1-0912 ซึ่งเป็นโมเดลที่มีชื่อเสียงในการแก้โจทย์เชิงตรรกะ
การฝึกโมเดลหลายขั้นตอน (Multi-Stage Training) ของ DeepSeek R1
ทีม DeepSeek ใช้กระบวนการฝึกแบบ 4 ขั้นตอน เพื่อหลีกเลี่ยงปัญหา cold start หรือความไม่เสถียรในช่วงต้นของการฝึก Reinforcement Learning (RL) โดยเริ่มจาก Supervised Fine-Tuning (SFT) ก่อนเข้าสู่การฝึกด้วย GRPO
เรามาเจาะลึกแต่ละขั้นตอน 🔍👇
Stage 1/4: Base to Supervised Fine-Tuning (SFT)
เป้าหมาย: เพิ่มความสามารถในการอ่าน (Readability) และความสอดคล้อง (Coherence) ของโมเดล
- วิธีการ:
- รวบรวมข้อมูล Chain-of-Thought (CoT) ที่มีความยาวสูงสุดถึง 10,000 tokens
- ใช้ โมเดล R1-zero ที่ปรับแต่งแล้ว และ human annotators (ผู้เชี่ยวชาญที่ติดป้ายกำกับข้อมูล)
- นำข้อมูลนี้มาปรับแต่ง DeepSeek V3 base
- Insight:
- การเพิ่ม CoT ทำให้โมเดลสามารถอธิบายกระบวนการคิดได้ชัดเจนขึ้น
- ปรับความสามารถของโมเดลในการให้เหตุผลตามลำดับขั้น (Step-by-Step Reasoning)
Stage 2/4: RL for Reasoning
เป้าหมาย: เสริมความสามารถในการให้เหตุผลที่ซับซ้อน (Reasoning-Intensive Tasks) เช่น การเขียนโค้ด (Coding) และ การคำนวณทางคณิตศาสตร์ (Mathematics)
- วิธีการ:
- ใช้กระบวนการฝึก RL แบบเดียวกับที่ใช้กับ R1-zero
- ใช้ Rule-Based Reward Models เพื่อตัดสินคำตอบ เช่น ความถูกต้องของผลลัพธ์ทางคณิตศาสตร์
- เพิ่มรางวัลใหม่: Language Consistency Reward → เพื่อให้โมเดลสื่อสารในภาษาที่สอดคล้องกัน
- Insight: การฝึกในขั้นนี้ช่วยให้โมเดลสามารถ ให้เหตุผลอย่างแม่นยำ และ อธิบายคำตอบได้ชัดเจน
- ตัวอย่าง: หากโมเดลต้องแก้โจทย์คณิตศาสตร์ในภาษาอังกฤษ ระบบจะลงโทษหากโมเดลตอบกลับเป็นภาษาอื่น
Stage 3/4: Rejection Sampling and SFT
เป้าหมาย: ขยายฐานข้อมูลด้วย Synthetic Data สำหรับงานทั่วไป
- วิธีการ:
- ใช้เทคนิค Rejection Sampling (RS) เพื่อสร้างชุดข้อมูลใหม่
- สร้างตัวอย่างจำนวน 600k ชุด สำหรับงานที่เน้นการให้เหตุผล
- สร้างอีก 200k ชุด สำหรับงานทั่วไป เช่น การเขียน (Writing) และ การจำลองบทบาท (Role-playing)
- ใช้ DeepSeek V3 เป็น Judge ในการประเมินคุณภาพของข้อมูลที่สร้างขึ้น
- Insight:
- Rejection Sampling ช่วยคัดเลือกเฉพาะ ตัวอย่างคุณภาพสูง
- เพิ่มความสามารถของโมเดลใน งานที่หลากหลาย ไม่จำกัดเฉพาะงานคณิตศาสตร์และการเขียนโค้ด
Stage 4/4: RL for Helpfulness
เป้าหมาย: พัฒนาความสามารถของโมเดลในการ ช่วยเหลือ (Helpfulness) และ ไม่เป็นอันตราย (Harmlessness)
- วิธีการ:
- ใช้ GRPO ร่วมกับโมเดลรางวัลแบบ Rule-Based และ Outcome-Based
- มุ่งเน้นให้โมเดลสามารถตอบคำถามได้อย่างมีประโยชน์และปลอดภัย
- ออกแบบรางวัลให้โมเดล หลีกเลี่ยงคำตอบที่อาจเป็นอันตราย (เช่น ข้อมูลที่ไม่เหมาะสม)
- Insight:
- ช่วยให้โมเดล เป็นมิตรกับผู้ใช้มากขึ้น (user-friendly)
- เพิ่มความสามารถในการ ให้ความช่วยเหลือที่เป็นประโยชน์ในหลากหลายบริบท
สรุป ทำไมการ เทรน Foundation Model ของ DeepSeek R1 ทำได้ดีกว่า OpenAI
- การปรับปรุง Group Relative Policy Optimization (GRPO) ซึ่งเป็นตัวฝึก AI ที่ช่วยพัฒนาความสามารถในการให้เหตุผลของโมเดล ให้มีประสิทธิภาพ ไม่จำเป็นต้องใช้โมเดลฟังก์ชันมูลค่า (Value Function Model) → ลดหน่วยความจำที่ใช้ ใช้ค่าเฉลี่ยของรางวัลในกลุ่มเป็นค่าฐาน (baseline) → ลดการคำนวณเพิ่มเติม
ซึ่งตรงนี้เองทำให้ ประหยัดทรัพยากรหน่วยความจำ (Memory) ลดความซับซ้อนในกระบวนการฝึก RL - Multi-Stage Training (การฝึกหลายขั้นตอน) ผสมผสานการ Supervised Fine-Tuning (SFT) กับ Reinforcement Learning (RL) SFT: ปรับแต่งโมเดลให้เชี่ยวชาญในงานพื้นฐาน RL: ใช้ GRPO เพื่อพัฒนาความสามารถด้านเหตุผล
ซึ่งส่งผลให้ ป้องกันความไม่เสถียรในช่วงต้นของ RL เร่งความเร็ว ในการปรับโมเดล (faster convergence) - Rule-Based Rewards (รางวัลตามกฎ) ให้รางวัลโดยใช้กฎเกณฑ์ที่กำหนดไว้ล่วงหน้า เช่น ความถูกต้อง (accuracy) และ รูปแบบ (format) ตอบโจทย์คณิตศาสตร์ถูกต้อง: +1 คะแนน อธิบายกระบวนการคิดในแท็ก ‘’ อย่างถูกต้อง: +1 คะแนน
ซึ่งตรงนี้เองทำให้ ไม่ต้องสร้างโมเดลรางวัลที่ซับซ้อน (General Reward Models) ลดการคำนวณเชิงลึกและการติดป้ายกำกับข้อมูล (Data Labeling) ซึ่ง ChatGPT อาจพึ่งพาโมเดลรางวัลที่ผ่านการฝึกกับความคิดเห็นของผู้ใช้ (RLHF) ซึ่งต้องใช้ข้อมูลที่มีการติดป้ายกำกับจำนวนมาก DeepSeek R1 ใช้กฎเกณฑ์ง่าย ๆ ซึ่งลดต้นทุนการจัดการข้อมูล - ไม่มีการใช้ Monte Carlo Tree Search (MCTS) หรือ Process Reward Models (PRM) ทั้งสองส่วนนี้เป็นการสร้างความซับซ้อน และเพิ่มต้นทุนการพัฒนา LLM
MCTS เป็นอัลกอริทึมที่ต้องคำนวณเส้นทางการตัดสินใจจำนวนมาก ซึ่งกินทรัพยากรมหาศาล ทำให้ต้นทุนการพัฒนาสูงขึ้น ส่วน PRM ต้องสร้างโมเดลรางวัลที่ติดตาม “กระบวนการคิด” (process-level reward) ซึ่งเพิ่มความซับซ้อนเช่นกัน
ซึ่งตรงนี้เองทำให้ ลดการคำนวณที่ไม่จำเป็น เน้นการฝึกที่ตรงเป้าหมายมากขึ้น เห็นชัดจาก ตอนที่ฝึกโมเดลเหตุผลทางคณิตศาสตร์ GRPO สามารถทำงานได้ดีโดยไม่ต้องพึ่ง MCTS ทำให้ DeepSeek R1 สามารถฝึกโมเดลได้เร็วและคุ้มค่ากว่ามาก
เปรียบเทียบความแตกต่างระหว่าง DeepSeek R1 และ ChatGPT
| หัวข้อ | DeepSeek R1 | ChatGPT (โดยทั่วไป) |
|---|---|---|
| เทคนิค RL | GRPO (ไม่มี Value Model) | PPO (มี Value Model) |
| ขั้นตอนการฝึก | Multi-stage: SFT + GRPO | PPO + RLHF |
| โมเดลรางวัล | Rule-based Rewards (กฎชัดเจน) | General Reward Models |
| การใช้ MCTS/PRM | ❌ ไม่ใช้ | ✅ อาจใช้ในงานบางประเภท |
| ความซับซ้อน | ง่ายกว่า (เปรียบเทียบภายในกลุ่ม) | ซับซ้อนกว่า (ใช้โมเดลรางวัลที่เรียนรู้จากผู้ใช้) |
| ต้นทุนฝึก | มีแนวโน้มต่ำกว่า (อิงจากโครงสร้าง) | สูงกว่า (ต้องใช้ข้อมูลที่ติดป้ายกำกับจำนวนมาก) |
ทั้งหมดคือ สิ่งที่ผมพยายามรวบรวมมาเพื่ออธิบายแนวทางใหม่ที่ DeepSeek R1 ผู้พลิกโฉม เปลี่ยนภูมิทัศน์ AI คนในซิลิคอนแวลลีย์ และทั่วโลก เพื่อให้ทุกคนเข้าใจลึกขึ้น ได้ข้อมูลที่ถูกต้อง และสามารถเข้าใจได้ง่ายขึ้น จากการเล่าเรื่องที่พยายามเรียบเรียงและขยายความให้ทุกท่านได้เข้าใจ แต่ก็ยัง Geek อยู่ดี 555
สุดท้ายยังมีความท้าทายของ Model ผู้พัฒนาชาวจีนอีกมากที่ต้องเรียกความเชื่อมั่น และความเสี่ยงที่อาจโดนปิดกั้น Open Source ต่าง ๆ ซึ่งเป็นเทคโนโลยีที่ทีม DeepSeek เข้าถึง ก็อาจกลายเป็นข้อจำกัดในการพัฒนาเช่นกัน การทำให้เกิดความเปลี่ยนแปลงการนำไปใช้งาน และการครองส่วนแบ่งตลาดก็ยังเป็นเรื่องที่ต้องรอดู ศึกนี้สำหรับ 2 ผู้ทรงอิทธิพลของโลก ยังอยู่ในช่วงเริ่มต้นเท่านั้น ขอบคุณที่อ่านมาถึงตรงนี้ครับ
Citation : Wire.com , Philipp Schimid : deepseek-r1 , Huggingface.co
PPO paper: https://arxiv.org/abs/1707.06347
- AIME ย่อมาจาก American Invitational Mathematics Examination ซึ่งเป็นการสอบคณิตศาสตร์ระดับสูงที่จัดขึ้นในสหรัฐอเมริกา เพื่อคัดเลือกนักเรียนเข้าสู่การแข่งขันคณิตศาสตร์ระดับประเทศ (USAMO) การประเมินผลในที่นี้ใช้เกณฑ์ “Pass@1” ซึ่งหมายถึงความสามารถของโมเดลในการตอบคำถามได้ถูกต้องในความพยายามครั้งแรก คะแนน Pass@1 ที่สูงบ่งชี้ว่าโมเดลมีความสามารถในการแก้ปัญหาคณิตศาสตร์ที่ซับซ้อนได้ดี ↩︎
- Codeforces เป็นแพลตฟอร์มการแข่งขันเขียนโปรแกรมที่ได้รับความนิยมอย่างมากในวงการโปรแกรมเมอร์ การประเมินผลในที่นี้ใช้เกณฑ์ “Percentile” ซึ่งแสดงถึงเปอร์เซ็นต์ของผู้เข้าร่วมที่โมเดลสามารถทำคะแนนได้ดีกว่า ตัวอย่างเช่น หากโมเดลอยู่ในเปอร์เซ็นไทล์ที่ 90 หมายความว่าโมเดลทำคะแนนได้ดีกว่า 90% ของผู้เข้าร่วมทั้งหมด การวัดผลนี้ช่วยประเมินความสามารถของโมเดลในการแก้ปัญหาการเขียนโปรแกรมที่ท้าทาย ↩︎
- GPQA ย่อมาจาก Graduate-Level Google-Proof Q&A Benchmark ซึ่งเป็นชุดคำถามที่ออกแบบมาเพื่อทดสอบความสามารถของโมเดล AI ในการตอบคำถามระดับบัณฑิตศึกษาในสาขาชีววิทยา ฟิสิกส์ และเคมี ชุดคำถาม “Diamond” เป็นชุดที่ยากที่สุดใน GPQA การประเมินผลใช้เกณฑ์ “Pass@1” เพื่อวัดความสามารถของโมเดลในการตอบคำถามที่ซับซ้อนและไม่สามารถค้นหาคำตอบได้โดยตรงจากอินเทอร์เน็ต ↩︎
- MATH-500 เป็นชุดคำถามคณิตศาสตร์ที่ประกอบด้วย 500 คำถาม ออกแบบมาเพื่อทดสอบความสามารถของโมเดลในการแก้ปัญหาคณิตศาสตร์ในระดับต่าง ๆ การประเมินผลใช้เกณฑ์ “Pass@1” เพื่อวัดความสามารถของโมเดลในการตอบคำถามได้ถูกต้องในความพยายามครั้งแรก ↩︎
- MMLU ย่อมาจาก Massive Multitask Language Understanding ซึ่งเป็นชุดการทดสอบที่ประกอบด้วยคำถามจากหลายสาขาวิชา เช่น ประวัติศาสตร์ วิทยาศาสตร์ และสังคมศาสตร์ การประเมินผลใช้เกณฑ์ “Pass@1” เพื่อวัดความสามารถของโมเดลในการทำความเข้าใจและตอบคำถามในหลาย ๆ หัวข้อ ↩︎
- WE-bench เป็นชุดการทดสอบที่ออกแบบมาเพื่อประเมินความสามารถของโมเดลในการแก้ปัญหาทางวิศวกรรมซอฟต์แวร์ การประเมินผลในที่นี้ใช้เกณฑ์ “Verified (Resolved)” ซึ่งหมายถึงจำนวนหรือเปอร์เซ็นต์ของปัญหาที่โมเดลสามารถแก้ไขได้สำเร็จและผ่านการตรวจสอบความถูกต้อง ↩︎
- การเรียนรู้แบบเสริมแรง (Reinforcement Learning หรือ RL) เป็นสาขาหนึ่งของการเรียนรู้ของเครื่อง (Machine Learning) ที่มุ่งเน้นให้เอเจนต์ (Agent) เรียนรู้การตัดสินใจในสภาพแวดล้อมที่เปลี่ยนแปลงได้ โดยมีเป้าหมายเพื่อเพิ่มผลตอบแทน (Reward) สะสมให้มากที่สุด
หลักการพื้นฐานของ Reinforcement Learning:
– เอเจนต์ (Agent): ผู้เรียนรู้หรือระบบที่ทำการตัดสินใจ
– สภาพแวดล้อม (Environment): โลกหรือสถานการณ์ที่เอเจนต์ทำงานอยู่
– สถานะ (State): ข้อมูลหรือสถานการณ์ปัจจุบันของเอเจนต์ในสภาพแวดล้อม
– การกระทำ (Action): สิ่งที่เอเจนต์เลือกทำเพื่อตอบสนองต่อสถานะ
– รางวัล (Reward): ค่าตอบแทนที่เอเจนต์ได้รับหลังจากทำการกระทำ
กระบวนการทำงาน:
เอเจนต์จะสังเกตสถานะปัจจุบันของสภาพแวดล้อม จากนั้นเลือกการกระทำที่คิดว่าจะให้รางวัลสูงสุด เมื่อทำการกระทำนั้นแล้ว สภาพแวดล้อมจะเปลี่ยนแปลงไปยังสถานะใหม่ และเอเจนต์จะได้รับรางวัลหรือการลงโทษตามผลของการกระทำนั้น กระบวนการนี้จะดำเนินไปเรื่อย ๆ ทำให้เอเจนต์เรียนรู้และปรับปรุงการตัดสินใจของตนเองเพื่อเพิ่มผลตอบแทนในระยะยาว ↩︎